
2017年11月19日 星期日
python on a stick / node.js on a stick
有些時候要 demo 一些東西,但是不能用自己的電腦,那麼就得想個方法,最好是不要安裝任何東西在 demo 的平台上,人家可能不答應,我們可能也擔心留下跟賣點有關的資訊甚至機密。node 在這種情況下相對單純,專案目錄和 node 目錄 copy 出來到 usb 上,手動指定 node 的執行位置,基本上就沒問題。 python 相對來講複雜許多,因為它可能很依賴一些 path 以及環境變數的設定。有人對解決方案做過一些 survey ,目前看來 WinPython 相對來說更新比較頻繁。也有人整理一些思路,例如撰寫 batch file 來設定所需的環境變數和目錄。 不過我想直接使用 WinPython 是比較簡單的~~
node.js 的部分,有人有討論過,也有人整理過流程。總之沒有要使用 npm 的話,事情就會單純許多。主程式的下載位置在 https://nodejs.org/dist/
2017年10月10日 星期二
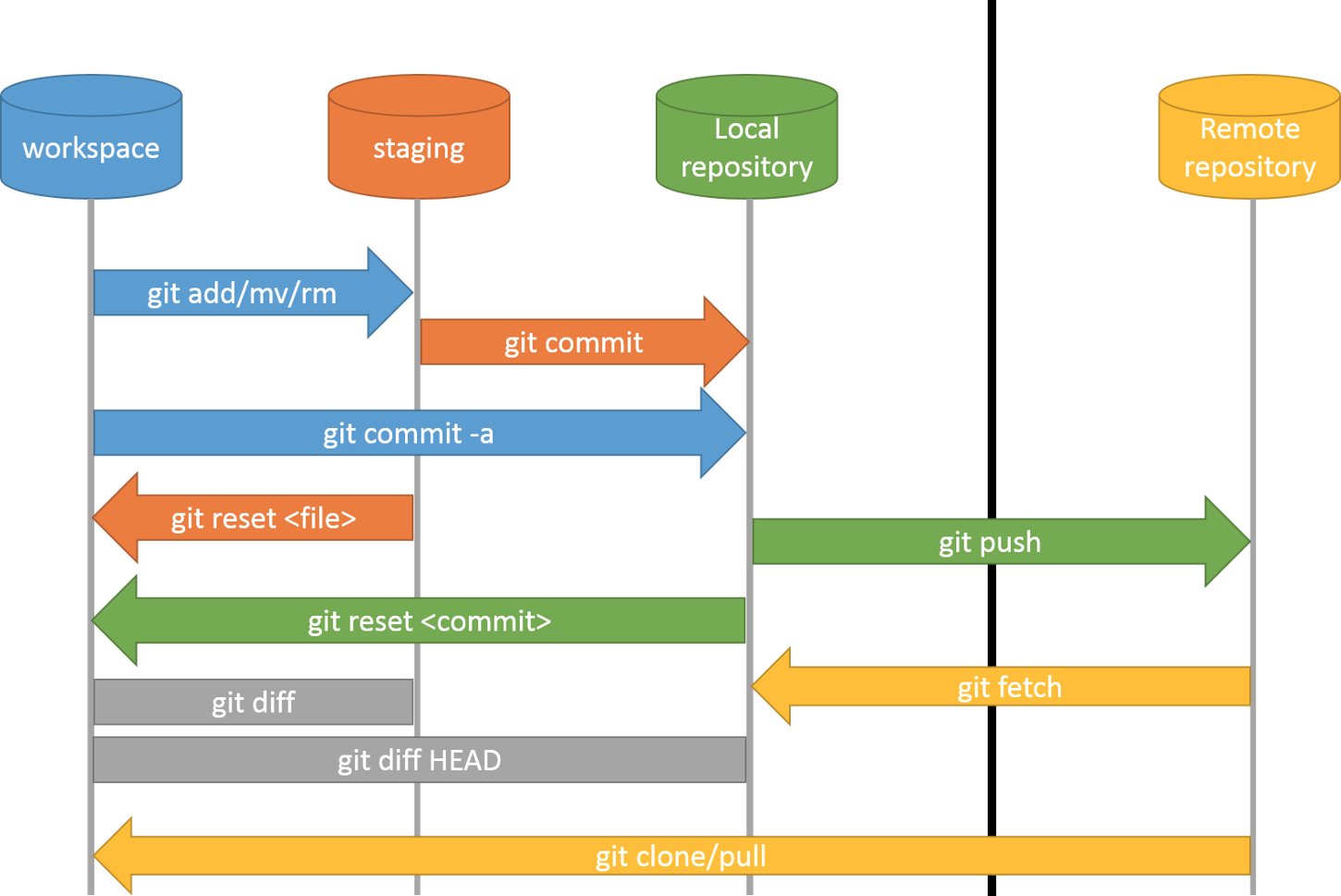
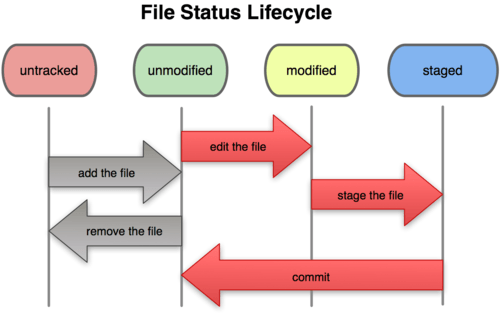
git pull --rebase 的前置作業
- git commit -m "..." #確定 staging area 清空
- git log 找出上次 checkout 的版本
- git diff 版本號 #確定 diff 的內容可以接受,沒有不需要的檔案、目錄,不然merge會很久
- git remote -v #確定 remote repository 的名稱
- git pull --rebase repo名 branch名
- 中間會有需要手動解決的情況,編輯該檔案,並記得 git add 該檔案,接著下 git rebase --continue (或skip),事後要確認檔案內容
在 local repo 中移除特定目錄
比較特別的是要在 local repo 中移除特定目錄,但保留在 working dir 當中,參考此帖
簡言之就是:
git rm -r --cached 目錄名
並請記得在 .gitignore 中加入對應的一行,以斜線"/"結尾,這樣才能順利 commit
2017年9月21日 星期四
DOM 文件中節點樹的遍歷 (traverse)
參 https://www.codeday.top/2016/11/15/1705.html
上述網頁列出了5種方式。搭配 DOM 的官方文件使用:https://www.w3schools.com/jsref/dom_obj_all.asp
上述網頁列出了5種方式。搭配 DOM 的官方文件使用:https://www.w3schools.com/jsref/dom_obj_all.asp
2017年8月27日 星期日
遠端 SSH 連線又要在斷線後保持工作進度的方式 -- screen
使用方法可參 使用 Screen 指令操控 UNIX/Linux 終端機的教學與範例
講重點:

講重點:
- screen 開新工作
- 做想做的事
- ctrl-A D 暫時離開 screen
- 重連時下 screen -r
網路不穩被斷線時,screen不會知道,所以重新登入時會無法連上。這時請:
- screen -lr 列出所有 session
- screen -d session_id,其中 id 可以打前幾個數字就好,角括號
- screen session_id
2017年8月19日 星期六
Stanford coreNLP的官方 python 介面-stanza-初探
官網 https://github.com/stanfordnlp/stanza
記得先 pip install requests ,安裝必需套件

記得先 pip install requests ,安裝必需套件
2017年8月15日 星期二
ubuntu 移動分割(partiton)的方式
參 https://help.ubuntu.com/community/MovingLinuxPartition
這是重寫過的版本,用到了安裝光碟。感覺上這個步驟比較保險
Step 1: Booting through Rescue CD
Step 2: Create new partition
Step 3: Clone Ubuntu partition to new location
Step 4: Generate and update UUID
Step 5: Update grub and fstab
Step 6: Update MBR to point the new grub
這是重寫過的版本,用到了安裝光碟。感覺上這個步驟比較保險
Step 1: Booting through Rescue CD
Step 2: Create new partition
Step 3: Clone Ubuntu partition to new location
Step 4: Generate and update UUID
Step 5: Update grub and fstab
Step 6: Update MBR to point the new grub
nvidia-docker 初探
參 https://hub.docker.com/r/nvidia/cuda/
原則上需要使用特製的 docker 版本: https://github.com/NVIDIA/nvidia-docker
不過它已經半年沒有動過了…
根據此文:https://github.com/NVIDIA/nvidia-docker/issues/429
nvidia-docker 近期內應該會上新版,並基於 https://github.com/nvidia/libnvidia-container 以方便 docker 改寫來支援更多平台
原則上需要使用特製的 docker 版本: https://github.com/NVIDIA/nvidia-docker
不過它已經半年沒有動過了…
根據此文:https://github.com/NVIDIA/nvidia-docker/issues/429
nvidia-docker 近期內應該會上新版,並基於 https://github.com/nvidia/libnvidia-container 以方便 docker 改寫來支援更多平台
2017年8月7日 星期一
syntaxnet 初探
說真的只是要摸個大概水準,不必要真槍實彈的搞,docker 的好現在就讓你知道
參 https://my.oschina.net/dingdayu/blog/1083438

看來要追上 coreNLP 還需要一點時間…
參 https://my.oschina.net/dingdayu/blog/1083438
- docker run -it tensorflow/syntaxnet bash
- cd /opt/tensorflow/syntaxnet
- wget http://download.tensorflow.org/models/parsey_universal/Chinese.zip
- unzip Chinese.zip
- MODEL_DIRECTORY=/opt/tensorflow/syntaxnet/Chinese
- echo '第一年住院医师,做阑尾切除手术时,找不到阑尾在何处,你若是他的主治医师,请你告诉他下列何种方法最容易找到阑尾?' | syntaxnet/models/parsey_universal/tokenize_zh.sh $MODEL_DIRECTORY | syntaxnet/models/parsey_universal/parse.sh $MODEL_DIRECTORY

看來要追上 coreNLP 還需要一點時間…
2017年8月4日 星期五
ubuntu 14.04上 docker / anaconda or virtualenv / tensorflow 的安裝
docker
其實我滿驚訝 docker 不是預裝套件的,而更驚的是套件名為 docker.io 而不是 docker!!安裝方式參 https://docs.docker.com/engine/installation/linux/docker-ce/ubuntu/#install-using-the-repository
事後回過頭來看,docker使用的空間還滿驚人的,建議限縮在固定大小的分割,作法分兩步:
win10可參考 https://forums.docker.com/t/where-are-images-stored/9794 ,請不要用cmd.exe,只能用powershell
至於我現在所執行的17.06.0穩定版本,在設定的地方已經可以直接設定

anaconda3(or virtualenv , preferred by tensorflow)
這可裝可不裝,要裝當然是裝 anaconda3 ;參 https://www.continuum.io/downloads基本上都推薦用 *.sh 直接安裝。
conda 的使用可看 https://www.digitalocean.com/community/tutorials/how-to-install-the-anaconda-python-distribution-on-ubuntu-16-04 , 有助於養成好習慣
(至於為何不用 ubuntu 16.04 呢?那又是另外一個浪費我一天生命的故事了 ( ′-`)y-~ (唉..這就是人生哪...))
那執迷不誤要用widnows的捧油,請不要用powershell,只能用cmd.exe(與docker相反,易混淆!!)
cuda
這可裝可不裝,裝了當然是佔空間,但換來較快的速度,載點: https://developer.nvidia.com/cuda-downloadstensorflow
之後裝 tensorflow,參 https://anaconda.org/conda-forge/tensorflow (人家包好的),或 http://yenlung-blog.logdown.com/posts/1598592 (自己編譯)win10 + pip3 安裝參 https://www.tensorflow.org/install/install_windows
win10 + anaconda 安裝參 http://darren1231.pixnet.net/blog/post/341911221
心得
說明文件、錯誤訊息都爛到不行,看來是故意想讓人裝不好(誤)再提供兩個網頁,記得要核實它們說的每一步,tensorflow的錯誤訊息完全、絕對不可信
How to install TensorFlow with GPU support on Windows 10 with Anaconda
Install TensorFlow with GPU for Windows 10
win10 上請愛用 sysdm.cpl ,隨時查核環境變數設定
(裝好後又開始嫌算力不足了…真是個無底洞)
2017年8月3日 星期四


2017年8月1日 星期二
使用Python進行數據分析 (I) anaconda / ipython / jupyter notebook 的安裝與執行
參考這個非常棒的影片 IPython 安裝與執行(使用Anaconda) - Python 與數據分析| U.camdemy
完整的課在這裏
這個影片的作者是政大的蔡炎龍老師
這是作者的一個說明網頁 [Python] IPython 的 Notebook 界面
作者的個人網頁 炎龍老師的教學研究網
為何要用它呢? 這位網友說得好:極其方便的紀錄實驗步驟
就是下載 anaconda 並安裝。值得注意的是,ipython 在新版已改為 jupyter
在命令列下達 jupyter notebook ,會開啟一個瀏覽器的頁籤,顯示所在目錄的內容
darren網友的網誌
不使用 anaconda 的安裝方式

完整的課在這裏
這個影片的作者是政大的蔡炎龍老師
這是作者的一個說明網頁 [Python] IPython 的 Notebook 界面
作者的個人網頁 炎龍老師的教學研究網
為何要用它呢? 這位網友說得好:極其方便的紀錄實驗步驟
安裝
就是下載 anaconda 並安裝。值得注意的是,ipython 在新版已改為 jupyter
執行
在命令列下達 jupyter notebook ,會開啟一個瀏覽器的頁籤,顯示所在目錄的內容
更多
darren網友的網誌
不使用 anaconda 的安裝方式
2017年6月28日 星期三
電腦三不五時停止回應,以往都是GoogleUpdateTaskUser,這回是 NvTmMon 搞的鬼


這兩年來至少每個禮拜都會發作個兩次,這回終於(不小心)被我抓到了
其實是在 debug 另一支排程程式時,覺得這裏可能有點線索,於是啟動了工作歷程記錄
剛好又發作一次,看看 log 才發現…
我只能心中送出 WTF+TMD !!! 這幾支程式可惡的地方在於它平常不會有特別的動作。
但是當你執行高 CPU 負載工作時,它似乎會很有興趣的想 "Monitor" 一下,結果機器整個 freeze
將近20~60秒後, windows 的 QueueReporting 接手記錄這個事件,又凍結15秒
關閉 NvTmMon 方式可參考 Disable Nvidia Telemetry tracking on Windows
哼反正要換 OS 了…
2017年6月19日 星期一
使用 perl one liner 進行檔案搜尋取代的流程(SOP)(二)
承接 使用perl one liner進行檔案搜尋取代的流程(SOP) 一文的第 2 步驟,由於使用 one-liner 時如果要進行取代,沒有什麼空間去做額外的判斷,因此在取代字串很可能必需向前參考所找到的 subgroup 。全寫在一行易讀性的確滿不好,但是這是 perl 的簡潔所必需付出的代價。
原理參考:
http://www.perlmonks.org/?node_id=687031
http://perldoc.perl.org/perlretut.html#Non-capturing-groupings
例如想把文字:
**** 67
取代成
**** 67 :drill:
在 windows 平台上的寫法是像這樣的:
perl -ne "print if s/^(\*+ \d+[ \t]+)?$/eval q{\"$1:drill:\"}/e and defined $1" abc.txt
或是更簡潔一點:
perl -ne "print if s/^(\*+ \d+[ \t]+)?$/q{\"$1:drill:\"}/ee and defined $1" abc.txt
一樣的道理可推到第 3、4 步,但不用去 test 有沒有發生取代:
perl -pe "s/^(\*+ \d+[ \t]+)?$/q{\"$1:drill:\"}/ee" abc.txt
perl -pi -e "s/^(\*+ \d+[ \t]+)?$/q{\"$1:drill:\"}/ee" abc.txt

原理參考:
http://www.perlmonks.org/?node_id=687031
http://perldoc.perl.org/perlretut.html#Non-capturing-groupings
例如想把文字:
**** 67
取代成
**** 67 :drill:
在 windows 平台上的寫法是像這樣的:
perl -ne "print if s/^(\*+ \d+[ \t]+)?$/eval q{\"$1:drill:\"}/e and defined $1" abc.txt
或是更簡潔一點:
perl -ne "print if s/^(\*+ \d+[ \t]+)?$/q{\"$1:drill:\"}/ee and defined $1" abc.txt
一樣的道理可推到第 3、4 步,但不用去 test 有沒有發生取代:
perl -pe "s/^(\*+ \d+[ \t]+)?$/q{\"$1:drill:\"}/ee" abc.txt
perl -pi -e "s/^(\*+ \d+[ \t]+)?$/q{\"$1:drill:\"}/ee" abc.txt
2017年5月14日 星期日
WannaCry 類電腦病毒防堵方式--立即關閉SMB服務並重開機
以windows 10為例:
1.按"視窗鍵"+Q,鍵入(或複製並貼上下列高亮文字):"windows 功能"後按下"開啟或關閉windows功能"
 2.往下捲,找到SMB並取消勾選,按"確定"
2.往下捲,找到SMB並取消勾選,按"確定"
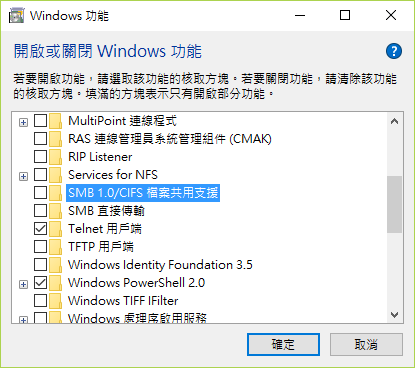
3.立即重開機
1.按"視窗鍵"+Q,鍵入(或複製並貼上下列高亮文字):"windows 功能"後按下"開啟或關閉windows功能"
3.立即重開機
2017年3月11日 星期六
各種模擬的瀏覽器
之前在2014年7月的 使用perl操控firefox: 基於selenium的解決方案 我曾經提到 selenium 這個由程式所模擬的瀏覽器,通常是為了測試而需要有一個能以 api 去操作的 browser 。github 上的這篇 https://gist.github.com/evandrix/3694955 回顧了10種browser ,依使用的程式語言不同,條列於下:
SimpleBrowser 輕量化的解決方案
spynner 一直都持續在更新中
twill 很久沒更新了
Zombie.js 一直都持續在更新中,4k+個star
env-js 很久沒更新了
.net
Awesomium 重量級的解決方案SimpleBrowser 輕量化的解決方案
java
HtmlUnit 一直都持續在更新中,但 host 在 sourceforge 上phthon
Ghost.py 一直都持續在更新中,2k+個starspynner 一直都持續在更新中
twill 很久沒更新了
ruby
watir 一直都持續在更新中,架構在 selenium 上Node.js
PhantomJS 這是我覺得最有前景的一個解決方案,畢竟 javascript 的 evaluation 在它來說根本就是 native 的;一直都持續在更新中,21k+個starZombie.js 一直都持續在更新中,4k+個star
env-js 很久沒更新了
2017年3月4日 星期六
2017年2月28日 星期二
windows 上沒有 wget 的解決方式
LWP::Simple 的getprint 由於沒有指定 User-Agent ,因此經常得到 403 的回應,所以要給個 header
perl -MLWP::UserAgent -e "print LWP::UserAgent->new(agent => 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36')->get('http://abc.def/ghi')->decoded_content"
http://abc.def/ghi 請代換為所需要的網址
其它的 header 可以在瀏覽器按 F12 查看

perl -MLWP::UserAgent -e "print LWP::UserAgent->new(agent => 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36')->get('http://abc.def/ghi')->decoded_content"
http://abc.def/ghi 請代換為所需要的網址
其它的 header 可以在瀏覽器按 F12 查看

2017年2月25日 星期六
文章中,中英並列的意涵
在以 corenlp 分析文章時,如果有中英並列的情況,會得到一個 parataxis 標注:

網路字典上查 parataxis :
不過我覺得比較好的翻譯是 中進英翻譯系列講座(四) 中所謂的"意合"。
順帶一提,文章中出現這種情況時,意合的文字代表的重要性就更高了,通常都可以拿來當作文章的關鍵字。
中文由於傾向意合,因此在剖析、分詞的時候,更容易造成模擬兩可:

"臨床上"和"麻醉下齒槽神經"的上/下,其實是具有不同的詞性,某方面要先知道有"下齒槽神經"這個術語,但是英文會這樣說:
網路字典上查 parataxis :
n. 名詞 【語言學】(不用連接詞的)並列結構[關系];並列排比;意合法〈使幾個分句不用連接詞而排列起來,例如:I came, I saw, ...
不過我覺得比較好的翻譯是 中進英翻譯系列講座(四) 中所謂的"意合"。
順帶一提,文章中出現這種情況時,意合的文字代表的重要性就更高了,通常都可以拿來當作文章的關鍵字。
中文由於傾向意合,因此在剖析、分詞的時候,更容易造成模擬兩可:

"臨床上"和"麻醉下齒槽神經"的上/下,其實是具有不同的詞性,某方面要先知道有"下齒槽神經"這個術語,但是英文會這樣說:
Where would you inject for an inferior alveolar nerve block?或是
When an Inferior Alveolar Nerve Block is performed, where is the anaesthetic injected?介系詞和冠詞的功用,在此明顯可見
2017年2月21日 星期二
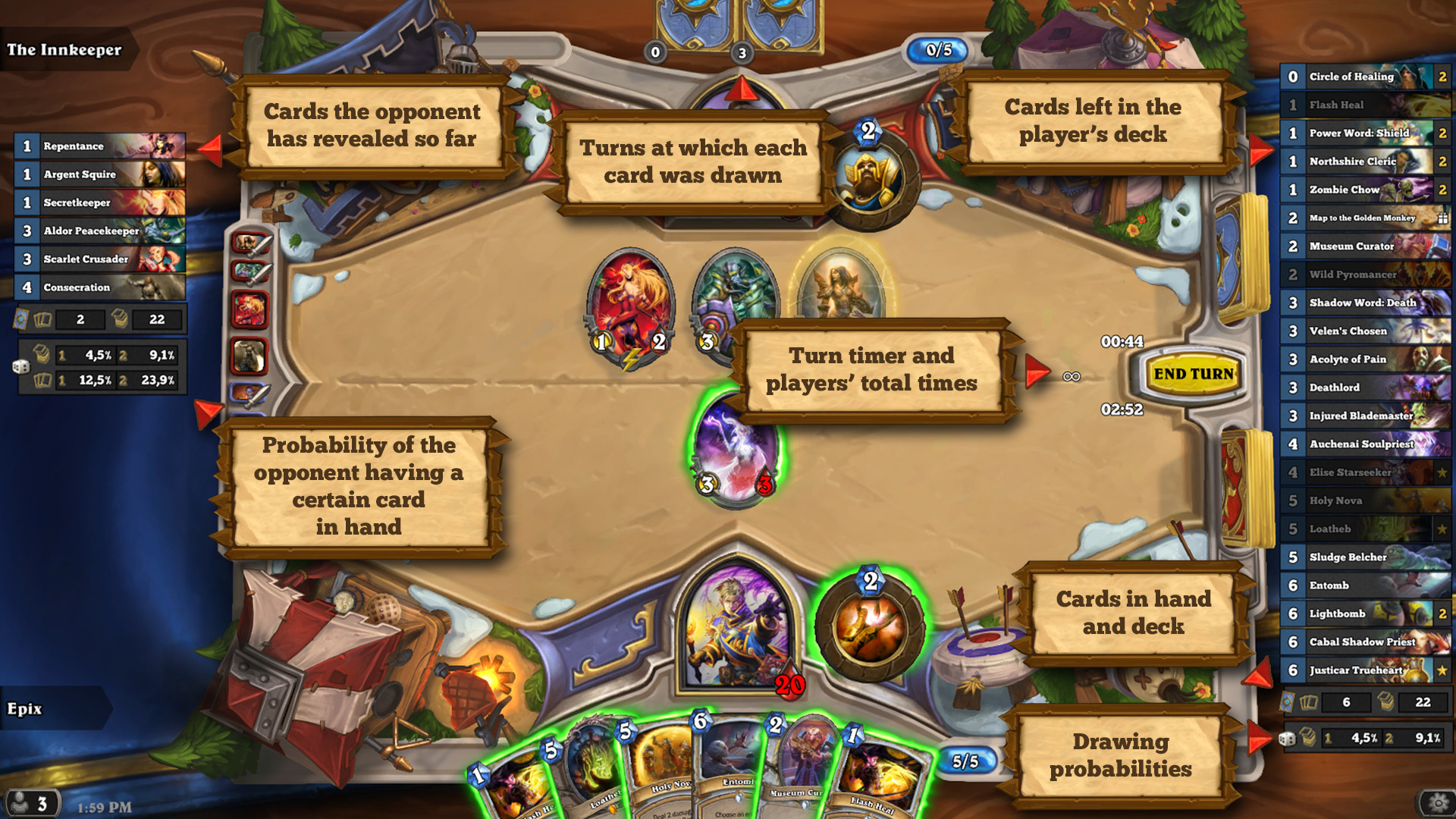
自己帶牌打爐石(誤)
去年 AlphaGO 大勝人類之後,曾經有風聲傳出它即將挑戰卡牌遊戲 "爐石戰記" ,研究了一下發現它的通訊協定早已被破解, github 上有人做了整理:Understanding the Hearthstone Protocol ,所以顯然是滿 doable 的。
這些開發者成立一個網站在 https://hearthsim.info/ ,有這麼一句話:
It was used by the DeepMind team at Google for Hearthstone card generation.
其最新一代作品叫 flireplace ,網址在 https://github.com/jleclanche/fireplace
https://github.com/HearthSim 上列出了一些其它的作品,如牌組計算的 https://github.com/HearthSim/Hearthstone-Deck-Tracker ,安裝版可下載自 https://hsdecktracker.net/
過年期間玩了一陣子,覺得這麼複雜的規則竟然能吸引這麼多人去精通,那麼把生活上的一些(冷)知識、時事等等,做成一套牌組來 KUSO 應該也是滿有趣、又富有教育意義的吧。
這些開發者成立一個網站在 https://hearthsim.info/ ,有這麼一句話:
It was used by the DeepMind team at Google for Hearthstone card generation.
其最新一代作品叫 flireplace ,網址在 https://github.com/jleclanche/fireplace
https://github.com/HearthSim 上列出了一些其它的作品,如牌組計算的 https://github.com/HearthSim/Hearthstone-Deck-Tracker ,安裝版可下載自 https://hsdecktracker.net/
過年期間玩了一陣子,覺得這麼複雜的規則竟然能吸引這麼多人去精通,那麼把生活上的一些(冷)知識、時事等等,做成一套牌組來 KUSO 應該也是滿有趣、又富有教育意義的吧。
2017年2月15日 星期三
玩轉 corenlp(2)
第一次執行時可能要做此初始化,速度比較慢,之後速度就很快了。
如果中文的部分出來的結果不好,我覺得常常是專門用語的問題,例如:

"促"這個字單獨出現時,記憶中也只有 TSH 有這種形容詞的詞性,怨不得 CoreNLP 了
P.S. 使用 ant 編譯後,我沒有壓成 jar ,所以執行方式要修正一下:
java -Xmx4g -cp "*;classes" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -serverProperties StanfordCoreNLP-chinese.properties -port 9000 -timeout 15000
如果中文的部分出來的結果不好,我覺得常常是專門用語的問題,例如:

"促"這個字單獨出現時,記憶中也只有 TSH 有這種形容詞的詞性,怨不得 CoreNLP 了
P.S. 使用 ant 編譯後,我沒有壓成 jar ,所以執行方式要修正一下:
java -Xmx4g -cp "*;classes" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -serverProperties StanfordCoreNLP-chinese.properties -port 9000 -timeout 15000
2017年2月11日 星期六
一些縮短 perl 程式行數的小技巧
用兩個等長陣列建構 hash
@hash{@keys} = @values
參 http://stackoverflow.com/questions/16755642/perl-built-in-function-to-zipper-together-two-arrays
順便一提,很多時候我們都忘記了, list 和 array 是不同的資料結構。 list 是 literal ,不是一種變數的形態,只是我們經常以 list 來初始化 array (以及 hash )。
my %parataxis=(); #empty hash
my @parataxis=(); #empty array
但是如果初始化的是一個參考資料型態,不管是 hash 或 array ,都有各自的符號 {} / []
my $parataxis={}; #empty hash ref
my $parataxis=[]; #empty array ref
簡單迴圈以 map / grep 處理陣列,以 split / join / splice 處理字串
泛 C 程式語言經常以 { } 括號來表示一個 block ,但是無形中也產生了一、兩個很稀疏的冗行。 python 嘗試以縮排解決這個問題,效果滿不錯的。 perl 的話其實 map 就是一個迴圈,用得好的話可以讓程式很精簡…
將一個陣列插入到另一個陣列
參 https://perlmaven.com/how-to-insert-an-array-into-another-array-in-perl
可以分為兩種情況,扁平的或是層級的插入,主要以 splice 函數實作

圖片來源:https://hsto.org/getpro/habr/post_images/707/723/436/70772343650f66c353ad80a06d5272ca.jpg
2017年2月9日 星期四
TF-IDF 以整體稀有度加權來計算詞彙重要性,以決定文件的關鍵詞
打關鍵字可以找出一堆網頁,但是有說明力的網頁,在設計和撰寫上是有一些工夫的。
我個人滿喜歡 文本分析初探 裏的說明,一是在第一頁就講到重點,二是適當的使用實例和圖片/公式,這篇的觀眾就是大眾導向。
排名較高的如 TF-IDF Text-mining 演算法 使用的是很正規的公式,這在翻成程式碼時很直觀,每個下標都對應一個迴圈;但是很多讀者是害怕數學公式的( formula-phobia ),當然例子舉得很好,這篇的觀眾就是工程師導向。
用我的話再解釋一次 tf-idf 的話,假設有 m 份文件, n 種辭彙:
我個人滿喜歡 文本分析初探 裏的說明,一是在第一頁就講到重點,二是適當的使用實例和圖片/公式,這篇的觀眾就是大眾導向。
排名較高的如 TF-IDF Text-mining 演算法 使用的是很正規的公式,這在翻成程式碼時很直觀,每個下標都對應一個迴圈;但是很多讀者是害怕數學公式的( formula-phobia ),當然例子舉得很好,這篇的觀眾就是工程師導向。
用我的話再解釋一次 tf-idf 的話,假設有 m 份文件, n 種辭彙:
- tf 就是 m X n 大小的矩陣,每個元素是該辭彙在該文件中出現的次數(可做些正規化)
- df 就是長為 n 的向量,每個元素是包含該辭彙出現的文件數(佔總文件數的比例)
- idf 就是 df 的倒數,為免發生除以 0 的情況, idf = 1 / (1 + df)
- tf-idf 就是 tf 的每個值對於對應的辭彙做加權
這種計算其實有點 arbitrary .臨界值可能要有點取捨才能得到好的模型,各數值本身也可以做正規化以得到不同的結果。好處就是計算快,所以花點時間都能調出不錯的結果。
2017年2月8日 星期三
emacs 中列出/刪除特定行
2013年我寫過一篇 "使用perl one liner進行檔案搜尋取代的流程(SOP)"
今天遇到列出/刪除具有特定字串的行的問題,發現 perl one liner 只有取代的功能,行是無法刪除的,而且在 windows 平台上,perl one liner 遇到 utf8 滿不好使的。http://xahlee.org/emacs/elisp_list_matching_lines.html 這篇介紹了 list-matching-lines / delete-matching-lines 兩個指令,輕鬆完成任務啊!!!
要注意的是在 org-mode 下使用的話,要把所有大綱縮合起來,有顯示出來的文字是無法被刪除的~~
今天遇到列出/刪除具有特定字串的行的問題,發現 perl one liner 只有取代的功能,行是無法刪除的,而且在 windows 平台上,perl one liner 遇到 utf8 滿不好使的。http://xahlee.org/emacs/elisp_list_matching_lines.html 這篇介紹了 list-matching-lines / delete-matching-lines 兩個指令,輕鬆完成任務啊!!!
要注意的是在 org-mode 下使用的話,要把所有大綱縮合起來,有顯示出來的文字是無法被刪除的~~
2017年2月6日 星期一
perl socket 編程速查
基本原理 ,流程圖畫得真是好
小小飯粒範例 ,拿來做 trouble shooting 真是方便
分解動作 ,這種 while ($line = <$sock>) 的寫法邪惡精簡得很啊
console-based 的程式通常是啟動費時短,沒有(or不需要)多工的能力,用來服務單一客戶端之用。一旦出現 contraindication 時,就是 socket-based + non-blocking IO 程式出現的時機了,尤其是還可視負載將服務分散到不同主機上。直覺上就是這樣,只有一台機器的時候,就是排隊,不想排隊而假裝多工,只是讓大家都等,等得更久而已。讓人排隊,還不如讓它 timeout / 返回錯誤值,讓人可以利用等待的時間做其它的工作。所以單機的情況下真的需要多工嗎?這要先好好了解,才能知道接下來要做什麼。
所以回過頭來看,最開頭分享的三個連結,其實對一般日常的任務而言,已經是很足夠的了。
小小
分解動作 ,這種 while ($line = <$sock>) 的寫法
console-based 的程式通常是啟動費時短,沒有(or不需要)多工的能力,用來服務單一客戶端之用。一旦出現 contraindication 時,就是 socket-based + non-blocking IO 程式出現的時機了,尤其是還可視負載將服務分散到不同主機上。直覺上就是這樣,只有一台機器的時候,就是排隊,不想排隊而假裝多工,只是讓大家都等,等得更久而已。讓人排隊,還不如讓它 timeout / 返回錯誤值,讓人可以利用等待的時間做其它的工作。所以單機的情況下真的需要多工嗎?這要先好好了解,才能知道接下來要做什麼。
所以回過頭來看,最開頭分享的三個連結,其實對一般日常的任務而言,已經是很足夠的了。
2017年2月4日 星期六
windows 平台以 cpan 安裝 POE
其實原本對在 windows 上 run 這個模組不抱什麼期望的,不知那來一個靈感,打了 cpan 後竟然發現立刻就裝了 mingw / dmake 等工具,然後在 cpan> 的提示下 notest install POE 就…安裝完成惹!!(大驚)
加上 notest 是因為有一步 build test 過不了,但是似乎沒什麼要緊,所以就乾脆跳過吧~~
加上 notest 是因為有一步 build test 過不了,但是似乎沒什麼要緊,所以就乾脆跳過吧~~
2017年2月2日 星期四
emacs / tmux 的準IDE化設置
4年前寫了兩篇文章,提到準IDE化設置及 buffer 的管理,今天不小心逛到一位神人 Baris Yuksel 所錄的幾部影片 Emacs as a C/C++ Editor/IDE ,共有四集,建議從第一集開始看,心領神會後一定會讚嘆 seafood emacs 是如此的一把神器。 gdb 的部份我本來以為滿難用的,但是看了這部 CppCon 2015: Greg Law " Give me 15 minutes & I'll change your view of GDB" 真是講得好,只是講者沒有前面提到的 Baris 剪接影片的能力,不然3分鐘就可以講完了說。
另外 tmux 也可以做到滿不錯的類似 emacs + eshell 的效果 , 只差在它不是文字編輯器了吧。
另外 tmux 也可以做到滿不錯的類似 emacs + eshell 的效果 , 只差在它不是文字編輯器了吧。
emacs 中等效於 ultraedit 的搜尋/多檔案搜尋指令,附上神人所錄下使用方式示範
ultraedit 單檔搜尋中有個好用的 list lines containing string, 在 emacs 中對應的組合鍵為 M-s o 及 M-x 。另外還有好用的多檔搜尋, M-x grep / M-x rgrep (遞迴搜尋整個目錄)。 詳情可看看這支影片 - Emacs Tutorial (Beginners) -Part 2- Buffer management, search, M-x grep and rgrep modes ,作者剪得真是好,該不會是 mac 中的什麼神器做的? 同作者錄了不少有趣的小短片,其中把 emacs 當 ide 的部份也滿不錯,非常值得一看。
2017年1月25日 星期三
You don't know shell-command (M-!) / eshell !!!
其實測試時能直接開 eshell 實在是很方便,做文件啦(尤其是 htmlfontify轉成 html)什麼的都很快捷。說到 emacs 的 eshell ,可以說是對 pipeline 及 createprocess 相當高段的一個創作。這一定要推薦 Mastering Emacs 這本書,很多時候可能要寫個小小 script 的工作,在 eshell 裏面竟然給幾個組合鍵就搞定了。
shell-command
先來說說 shell-command 。 在 ultraedit 中有幾個很方便的功能,例如 Alt-E,F 可以複製檔案名稱到剪貼簿中,經常搭配著 cmd.exe 來進行各種工作。 emacs 可以做類似的事,例如 M-! pwd (linux 系統上) 或 M-! cd (windows系統上),但是它少了複製/貼上的冗餘動作,只要在下命令前加上 C-u 即可使輸出結果插入當前 buffer 中。
C-u M-! 這個按鍵組合本身就是個經典, 例如 C-u M-! ping xxx.xxx.xxx.xxx ,就可以把ping的結果直接插入到當前文件,這要直接在 cmd.exe 上要多作很多的動作(需要滑鼠),想到就很讚嘆…
其它詳情請參考 https://www.masteringemacs.org/article/executing-shell-commands-emacs
eshell
詳情請參考 https://www.masteringemacs.org/article/complete-guide-mastering-eshell
雖然把它當 bash / cmd.exe 有點太小看它了,不過能在 buffer 中執行 shell 又能把結果立馬拿來編輯,這已經很好用了。
emacs 25.1-2 版
最後, emacs 25.1-2 版已經出了,有很多令人振奮的新功能,讓人覺得 rstudio / iphthon 的功能也被吸星大法吸納的港(?)覺
其中新的動態連結功能,可以想見即將取代目前大部分使用命令列參數來呼叫其它工具程式的局面,好處的話想當然爾可以節省多次呼叫時所需的啟動時間,壞處的話就是可能 lib 寫不好的話反而去掛掉主程式…真心覺得 jboss / websphere 這類服務有點危險, bash 等 shell 寫得愈來愈好,會寫 shell script 的人愈來愈多,回頭一看可能會發現,很多東西其實在 shell 的層級就可以很簡單的解決掉了…
其中新的動態連結功能,可以想見即將取代目前大部分使用命令列參數來呼叫其它工具程式的局面,好處的話想當然爾可以節省多次呼叫時所需的啟動時間,壞處的話就是可能 lib 寫不好的話反而去掛掉主程式…真心覺得 jboss / websphere 這類服務有點危險, bash 等 shell 寫得愈來愈好,會寫 shell script 的人愈來愈多,回頭一看可能會發現,很多東西其實在 shell 的層級就可以很簡單的解決掉了…
emacs 中 shell-command-to-string 的使用在 windows 平台上的一些想法/心得
shell-command-to-string 由於參數是呼叫平台本身預設 locale 的編碼,並非 unicode/utf-8 ,因此傳遞參數必需直接丟 cp950 編碼 ,印出時也必需是 cp950 ,不然會產生亂碼。 然而如果為了這個原因而必需維護 linux 及 windows 兩種程式版本,也是滿麻煩的。 我的建議是被呼叫端使用 base64 來解/編碼, emacs 端則以 (base64-encode-string (encode-coding-string XXX 'utf-8 t) t) 來傳送引數字串 XXX。
當然,多年以後可能會有比較深的領悟,覺得 emacs 也真是很辛苦的在向英文下相容這工作上下苦工。參考 Coding Systems in `shell-command` 上的說明,把 (setq default-process-coding-system '(utf-8 . utf-8)) 執行一下,就發現在 eshell 竟然可以直接輸入/輸出 utf8 字串了!! (cmd.exe 要在命令列輸入 unicode 也要另外設定,關鍵字 chcp ,網路上很多大大有詳解,就不在此掠美了。)
不過阿Q一點想,也是多學一些技能嘛~~
但是很多時候啟動一個應用程式的成本很高,不論是空間上或時間上的成本,這時候會有必要:
當然,多年以後可能會有比較深的領悟,覺得 emacs 也真是很辛苦的在向
不過阿Q一點想,也是多學一些技能嘛~~
但是很多時候啟動一個應用程式的成本很高,不論是空間上或時間上的成本,這時候會有必要:
- 改寫原程式為 socket server / web service,然後你要讀懂原程式…
- 利用 netcat 在 linux 平台上直接解決。不過當初原程式可能沒有想到它會有來自網路的要求,這額外的邏輯,是否能在 script shell 的層次解決,可能還是有點不確定性… 而且 netcat 只能接受一次連線的樣子,這只能做為一個一次性的任務之用,比如測試之類的,參 Linux nc 常見用法
- 那還是要自己寫個 script 比較妥當(正解)
寫 script 來直接呼叫程式又有兩種思路:
- 一種是由 ssh 呼叫,實際上是透過了 shell (sh/bash) 來執行程式,這比較偏向 linux-based 、 administrator-oriented 、 session-oriented 的解法,而且要搭配 session 或 tmux 來讓被呼叫的程式在背景執行,參 5 Ways to Keep Remote SSH Sessions and Processes Running After Disconnection ,再建立一個 tcp server 或 http server 來處理請求。
- 另一種是由 createprocess 來呼叫,再建立一個 tcp server 或 http server 來處理請求。
console-based (stdin/stdout) vs socket-based
上面說的外部應用程式都是傳統的 console 程式,emacs畢竟原生的 socket 支援滿差的,所以思路比較受限。但是如果應用程式的原生語言對 sockets 的支援不錯的話,其實建議直接寫 socket-based 程式,以 line 導向做 IO。甚至對 xml/jason 支援不錯的話,以 xml/jason 導向做IO,以避掉 EOF 的決定條件問題。


2017年1月14日 星期六
docker X windows10 X tensorflow X syntaxnet (1)
因為各種原因,2016年下半開始,docker終於在windows 10上有比較好用一點了

左邊的黑框中最下一行有密碼,點擊右邊的畫面可以帶出jupyter瀏覽器,輸入密碼即可進入根目錄,打開 1_hello_tensorflow.ipynb 就可以開始玩 tensorflow 了
請依 此網址 安裝,目前最新版是 1.12.6 ,安裝完成後再裝好 kitematic ,搜尋 tensorflow ,按下 create

左邊的黑框中最下一行有密碼,點擊右邊的畫面可以帶出jupyter瀏覽器,輸入密碼即可進入根目錄,打開 1_hello_tensorflow.ipynb 就可以開始玩 tensorflow 了
比較詳細的 docker for windows 安裝說明可參考 https://docs.docker.com/docker-for-windows/
深度學習近年來被炒得火熱,基於的多層 DNN 及單層的 HMM 在某種層次上都是對出象的模式識別,只是得力於 GPU 的能力,使得這些計算變得很便宜。
雖說這種暴力的、"湊答案"式的解空間映射,距離"人工智慧"的想像還差得遠了,但是日常工作中又有多少內容是真的需要"智慧"才能解決呢?
2017年1月3日 星期二
玩轉 corenlp
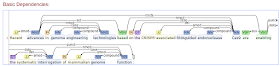
進入 http://corenlp.run/ ,輸入一個句子後,按下 Submit
結果節錄如下
這樣就可以用來寫個程式,丟到 SQuAD 試試了
參考 SyntaxNet in context: Understanding Google's new TensorFlow NLP model 一文,以 "They ate the pizza with anchovies" 一句為例丟進 corenlp ,果然得到比較好笑的那種結果。
看來要花點時間玩玩 SyntaxNet 了…
Recent advances in genome engineering technologies based on the CRISPR-associated RNA guided endonuclease Cas9 are enabling the systematic interrogation of mammalian genome function.
結果節錄如下

這樣就可以用來寫個程式,丟到 SQuAD 試試了
參考 SyntaxNet in context: Understanding Google's new TensorFlow NLP model 一文,以 "They ate the pizza with anchovies" 一句為例丟進 corenlp ,果然得到比較好笑的那種結果。
看來要花點時間玩玩 SyntaxNet 了…